💓博主CSDN主页:麻辣韭菜💓
⏩专栏分类:Linux初窥门径⏪
🚚代码仓库:Linux代码练习🚚
🌹关注我🫵带你学习更多Linux知识
🔝

前言
1. 生产消费者模型
1.1 什么是生产消费者模型?
1.2 生产消费者模型原则
1.3 生产消费者模型的优点
2. 基于阻塞队列实现生产消费者模型
2.1 单生产单消费模型
2.2 多生产多消费
3. POSIX 信号量
POSIX 信号量有两种类型:
POSIX 信号量的基本操作:
4. 基于循环队列实现生产消费者模型
4.1 多生产多消费
环形队列的优缺点:
阻塞队列的优缺点:
前言
生产者-消费者模型是一个经典的并发编程问题,它描述了两种角色:生产者和消费者。生产者负责生成数据,而消费者则负责消费这些数据。这个模型通常用于处理多线程或多进程环境中的资源分配问题。
1. 生产消费者模型
1.1 什么是生产消费者模型?
上面的名词有些抽象,我们直接用生活中案例来举例子,大家就会豁然开朗。
 超市工作模式:
超市工作模式:
超市需要从工厂拿货,工厂则需要提供给超市商品
消费者在超市消费,超市需要向顾客提供商品
超市的作用就是平衡消费者和工厂供需平衡
为什么这么说?
简单来说就是要做到 顾客可以在超市买到想要购买的商品,工厂也能同超市完成足量的需求订单,超市这样就可以为双方提供便利。
顾客再也不用到工厂去买商品
工厂也不需要将商品亲自送到顾客手中。
如果没有超市,顾客直接去工厂消费,工厂生产出来商品再送到顾客手中,这种关系就是高度相互依赖,离开谁都不能干。这就是传说中的强耦合关系。
超市的出现,极大了提高效率,从而顾客和工厂之间不再单方面的依赖。使得它们之间依赖度降低。而这就是传说的中解耦。
生产者消费者模型的本质:忙闲不均
我们再回到编程的视角
- 工厂 —> 生产者
- 顾客 —> 消费者
- 超市 —> 某种容器
这样我们就可以利用线程来干事了,线程充当生产者和消费者。利用STL的队列容器(缓冲区)充当超市。 常见的有 阻塞队列 和 环形队列
在实现中,超市不可能只面向一个顾客,一个工厂。在多线程中,也就意味着它们都能看到这个队列(超市),那么必须就要让线程之间存在互斥与同步。对于互斥与同步不理解的可以看 Linux 线程的同步与互斥
从上面我们就可以的得出它们之间关系。
生产者VS生产者:互斥

一张图解释一切,这么多汽车生产商,相互竞争,对于多线程之间也是一样,所以需要互斥。
消费者VS消费者:互斥
比如宝马4S店里,只剩最后一辆宝马7系,如果这时来了两个消费者,张三李四都想要这辆车,如果是张三先交了订金,那么李四就没有机会了,但是如果李四私下愿意加钱。那么张三和李四之间存在竞争。对于线程来说,我们需要互斥。
生产者VS消费者:互斥、同步
我们假设李四拿到了车,但是张三是个非常执着的人,其他车都不要,就要宝马7系。对于4S店来说,它就应该给工厂发消息生产7系车。然后再告诉张三有车了,进而消费。就对于生产线程和消费线程那就是同步。
如果宝马一直疯狂生产,也不管4S店到底卖出去没有,也不管消费者到底买不买,那么这样就乱套了。结局只有破产!!!所以需要根据消费者的需求来进行合理生产。反过来消费者和宝马也是同理。而这对于多线程来说,那就是互斥。
1.2 生产消费者模型原则
生产消费者模型原则:321原则
三种关系:
- 生产者VS生产者:互斥
- 消费者VS消费者:互斥
- 生产者VS消费者:同步、互斥
两种角色:
- 生产者
- 消费者
一个交易场所:
- 特定的容器:阻塞队列、环形队列
生产消费者模型原则,书本是没有这个概念,为了方便记忆,大牛提炼总结出来的。
1.3 生产消费者模型的优点
为什么生产消费者模型高效?
- 生产者、消费者 可以在同一个交易场所中进行操作
- 生产者在生产时,无需关注消费者的状态,只需关注交易场所中是否有空闲位置
- 消费者在消费时,无需关注生产者的状态,只需关注交易场所中是否有就绪数据
- 可以根据不同的策略,调整生产者于与消费者间的协同关系
生产消费者模型可以根据供需关系灵活调整策略做到忙闲不均。生产者和消费者无需关心他人的状态,做到并发。
2. 基于阻塞队列实现生产消费者模型
在正式编写代码前,我们先了解阻塞队列与普通的队列区别在于,当队列为空时,从队列获取元素的操作将会被阻塞,直到队列中被放入了元素;当队列满时,往队列里存放元素的操作也会被阻塞,直到有元素被从队列中取出(以上的操作都是基于不同的线程来说的,线程在对阻塞队列进程操作时会被阻塞)

2.1 单生产单消费模型
为了方便理解我们先用单生产、单消费的方式来讲解
先创建Blockqueue.hpp的头文件。
#include <iostream>
#include <queue>
#include <pthread.h>
template <class T>
class Blockqueue
{
static const int defaultnum= 10;
public:
Blockqueue(int maxcap = defaultnum)
: _maxcap(maxcap)
{
pthread_mutex_init(&_mutex, nullptr);
pthread_cond_init(&_c_cond, nullptr);
pthread_cond_init(&_p_cond, nullptr);
}
void push(const T &data) //生产数据
{
}
T pop() //取数据
{
}
~Blockqueue()
{
pthread_mutex_destroy(&_mutex);
pthread_cond_destroy(&_c_cond);
pthread_cond_destroy(&_p_cond);
}
private:
std::queue<T> _q;
int _maxcap; // 极值
pthread_mutex_t _mutex;
pthread_cond_t _c_cond; // 消费者
pthread_cond_t _p_cond; // 生产者
};阻塞队列框架搭建出来后,生产和消费我们后面实现。
由于我们是单生产单消费的生产消费者模型。所以
在mian.cc主函数中创建两个线程
#include "Blockqueue.cpp"
void * Consumer(void *args) //消费者
{
}
void * Productor(void *args) //生产者
{
}
int main()
{
Blockqueue<int> *bq = new Blockqueue<int>;
//创建线程(生产、消费)
pthread_t c,p;
pthread_create(&c,nullptr,Consumer,bq);
pthread_create(&p,nullptr,Productor,bq);
pthread_join(c,nullptr);
pthread_join(p,nullptr);
delete bq;
return 0;
}上面就是生产消费者模型的大致框架,我们在实现具体细节之前,我们先要明白一个关键问题。
生产和消费要不要耗费时间?
生产和消费是肯定要耗费时间的,一辆车不会平白无故的出现,车从生产到成品这个过程是要耗费大量的数据,同理作为消费者使用车,也是要耗费时间的。开车不需要耗费时间吗?
所以在代码层面角度来说:生产和消费都是需要耗费时间的,并不是一味的在阻塞队列里进行生产和消费。而是生产者在生产数据之前,要对数据做加工,做完之后才放进阻塞队列,消费者也不是从阻塞队列拿到数据就完事了,而是拿到数据之后,对数据做分析,然后决策。
为什么生产和消费只需要同一把锁?
因为它们两个是基于阻塞队列的,我们可以把阻塞队列看成一份整体资源,所以只需要一把锁,但是共享资源也可以被看做多份。
为什么生产和消费各自需要一个条件变量?
这就是为什么叫做阻塞队列。两个线程各自基于自己的条件变量,当条件不满足时候,那么就会阻塞等待。
明白这点之后 我们来实现生产和消费
生产和消费都能看到同一个阻塞队列,之前我们也说了生产和消费是既有同步又互斥的关系,那么生产线程和消费线程在访问阻塞队列时,只能是只有一个在访问。那么必然要互斥
void push(const T &data) //生产数据
{
pthread_mutex_lock(&_mutex);
_q.push(data);
pthread_mutex_unlock(&_mutex);
}生产是想生产就能生产的吗?
当然不是,阻塞队列如同超市一样,商品在货架上都放满了,生产出来的商品没有人买,那不是妥妥亏钱?
所以在生产之前还得问问超市,条件满足不?满足生产,不满足堵塞等待被唤醒
void push(const T &data) //生产数据
{
pthread_mutex_lock(&_mutex);
if(_q.size() == _maxcap)
{
pthread_cond_wait(&_p_cond,&_mutex);//不满足阻塞
}
_q.push(data);
pthread_cond_signal(&_c_cond);
pthread_mutex_unlock(&_mutex);
}当生产条件不满足的时候,那么生产线程要去等待。这里就有个问题,生产线程在访问条件满不满足的时候,是已经拿到了锁的,不释放锁去等待,那么会造成死锁的问题。所以我们利用
pthread_cond_wait函数 ,等待的同时解锁。
同理消费数据也是一样。
T pop() //消费数据
{
pthread_mutex_lock(&_mutex);
if(_q.size() == 0)
{
pthread_cond_wait(&_c_cond,&_mutex);//不满足阻塞
}
T out = _q.front();
_q.pop();
pthread_cond_signal(&_p_cond);
pthread_mutex_unlock(&_mutex);
return out;
}那么我们在实现了生产和消费之后,就需要在mian.cc中实现生产消费的回调函数
我们先srand函数模拟随机数
srand(time(nullptr) ^ getpid());#include <ctime>
#include <unistd.h>
void *Consumer(void *args) // 消费者
{
Blockqueue<int> *bq = static_cast<Blockqueue<int> *>(args);
while (true)
{
int t = bq->pop();
std::cout << "消费了一个数据..." << t << std::endl;
}
}
void *Productor(void *args) // 生产者
{
Blockqueue<int> *bq = static_cast<Blockqueue<int> *>(args);
while (true)
{
int data = rand() % 10 + 1;
bq->push(data);
std::cout << "生产了一个数据..." << data << std::endl;
sleep(1);
}
}

结果符合预期,生产和消费实现了同步互斥。但是我们就传入个整数,未免有点锉了,我们是用C++写的,而且我们blockqueue是带模板,我们可以传入对象。
先创建一个Task.hpp的头文件
我们在Task.hpp这个头文件中,创建一个Task类。在这个类中实现一些加减乘除的函数方法,由生产者生产任务。然后消费者拿到任务数据做加工
#pragma once
#include <iostream>
#include <string>
std::string opers = "+-*/%";
enum
{
DivZero = 1,
ModZero,
Unknown
};
class Task
{
public:
Task(int data1, int data2, char oper)
: _data1(data1), _data2(data2), _oper(oper), _result(0), _exitcode(0)
{
}
void run()
{
switch (_oper)
{
case '+':
_result = _data1 + _data2;
break;
case '-':
_result = _data1 - _data2;
break;
case '*':
_result = _data1 * _data2;
break;
case '/':
{
if (_data2 == 0)
_exitcode = DivZero;
else
_result = _data1 / _data2;
}
break;
case '%':
{
if (_data2 == 0)
_exitcode = ModZero;
else
_result = _data1 % _data2;
}
break;
default:
_exitcode = Unknown;
break;
}
}
std::string GetResult()
{
std::string r = std::to_string(_data1);
r += _oper;
r += std::to_string(_data2);
r += "=";
r += std::to_string(_result);
r += "[code: ";
r += std::to_string(_exitcode);
r += "]";
return r;
}
std::string GetTask()
{
std::string r = std::to_string(_data1);
r += _oper;
r += std::to_string(_data2);
r += "=?";
return r;
}
void operator()() //运算符重载让对象像函数一样使用
{
run();
}
~Task()
{
}
private:
int _data1;
int _data2;
char _oper;
int _result;
int _exitcode;
};void *Consumer(void *args) // 消费者
{
// Blockqueue<int> *bq = static_cast<Blockqueue<int> *>(args);
Blockqueue<Task> *bq = static_cast<Blockqueue<Task> *>(args);
while (true)
{
Task t = bq->pop();
t();
std::cout << "处理任务: " << t.GetTask() << " 运算结果是: "
<< t.GetResult() << " thread id: " << pthread_self() << std::endl;
}
}
void *Productor(void *args) // 生产者
{
// Blockqueue<int> *bq = static_cast<Blockqueue<int> *>(args);
Blockqueue<Task> *bq = static_cast<Blockqueue<Task> *>(args);
int len = opers.size();
while (true)
{
int data1 = rand() % 10 + 1;
int data2 = rand() % 10;
char oper = opers[rand() % len];
Task t(data1, data2, oper);
bq->push(t);
std::cout << "生产了一个任务: " << t.GetTask() << " thread id: " << pthread_self() << std::endl;
sleep(1);
}
}
注:
其实我们不用非要等到满了,才停止生产。我们可以定策略,就如同水库的警戒线,当河水上涨到警戒线时,就开闸放水,而不是等到水库满了才放。消费也是同理。
int low_water_;
int high_water_;2.2 多生产多消费
我们实现了单生产单消费,这里改成多生产多消费,非常简单。只需要在mian.cc这里循环创建线程即可
int main()
{
srand(time(nullptr) ^ getpid());
Blockqueue<Task> *bq = new Blockqueue<Task>;
// 创建线程(生产、消费)
pthread_t c[3], p[5];
for (int i = 0; i < 3; i++)
{
pthread_create(c + i, nullptr, Consumer, bq);
}
for (int i = 0; i < 5; i++)
{
pthread_create(p + i, nullptr, Productor, bq);
}
for (int i = 0; i < 3; i++)
{
pthread_join(c[i], nullptr);
}
for (int i = 0; i < 5; i++)
{
pthread_join(p[i], nullptr);
}
delete bq;
return 0;
}
出现上面的错误是因为伪唤醒的原因
为什么会出现伪唤醒的?

现在是多个线程了,也就是说当阻塞队列满时,所有的生产线程被阻塞等待被唤醒。消费线程这时消费一个数据,当阻塞队列不满时,那么就会唤醒所有的生产线程,3个线程只有一个线程能拿到锁,其中一个拿到锁线程进行生产此时阻塞队列已经满了。等其他线程拿到锁后,条件不满足。生产不了,这就是伪唤醒。
所以我们把if改成while 循环判断防止伪唤醒
void push(const T &data) // 生产数据
{
pthread_mutex_lock(&_mutex);
while (_q.size() == _maxcap) // 用while防止伪唤醒,判断条件满不满足
{
pthread_cond_wait(&_p_cond, &_mutex); // 不满足阻塞
}
_q.push(data);
pthread_cond_signal(&_c_cond);
pthread_mutex_unlock(&_mutex);
}
T pop() // 消费数据
{
pthread_mutex_lock(&_mutex);
while (_q.size() == 0) // 用while防止伪唤醒,判断条件满不满足
{
pthread_cond_wait(&_c_cond, &_mutex); // 不满足阻塞
}
T out = _q.front();
_q.pop();
pthread_cond_signal(&_p_cond);
pthread_mutex_unlock(&_mutex);
return out;
} 
这里我们直接用C++的锁。

std:: mutex _mutex;
void *Consumer(void *args) // 消费者
{
// Blockqueue<int> *bq = static_cast<Blockqueue<int> *>(args);
Blockqueue<Task> *bq = static_cast<Blockqueue<Task> *>(args);
while (true)
{
Task t = bq->pop();
t();
std::lock_guard<std::mutex> guard(_mutex);
std::cout << "处理任务: " << t.GetTask() << " 运算结果是: "
<< t.GetResult() << " thread id: "<< std::hex << pthread_self() << std::endl;
}
}
void *Productor(void *args) // 生产者
{
int len = opers.size();
// Blockqueue<int> *bq = static_cast<Blockqueue<int> *>(args);
Blockqueue<Task> *bq = static_cast<Blockqueue<Task> *>(args);
while (true)
{ sleep(1);
int data1 = rand() % 10 + 1;
int data2 = rand() % 10;
char oper = opers[rand() % len];
Task t(data1, data2, oper);
bq->push(t);
std::lock_guard<std::mutex> guard(_mutex);
std::cout << "生产了一个任务: " << t.GetTask() << " thread id: " << std::hex << pthread_self() << std::endl;
}
}

为什么只修改线程创建的代码,多线程就能适应原来的消费场景?
原因有2点:
- 生产者、消费者都是在对同一个
_queue操作,用一把锁,保护一个临界资源,足够了 - 当前的
_queue始终是被当作一个整体使用的,无需再增加锁区分
当然也可以让生产者和消费者各自拿一把锁,但是都是基于_queue的完全没有必要,画蛇添足。
3. POSIX 信号量
在 POSIX 标准中,信号量(semaphore)是一种用于控制多个进程或线程对共享资源访问的同步机制。信号量是一个计数器,它可以跟踪一定数量的资源或信号量单位。进程或线程可以通过原子操作对信号量进行增加或减少,从而实现对共享资源的协调访问。
也就是说,让线程的同步的方法,不仅仅只有条件变量,还有信号量。
POSIX 信号量有两种类型:
-
无名信号量(Unnamed semaphores):也称为进程间信号量,因为它们可以在不同的进程之间共享。无名信号量使用
sem_t类型表示,并通过sem_init()函数初始化,使用sem_destroy()函数销毁。无名信号量需要一个与之关联的键值来标识,这个键值可以通过ftok()或shmget()函数获得。 -
命名信号量(Named semaphores):也称为系统V信号量,它们是系统范围内唯一的,并且可以跨会话使用。命名信号量通过
semget()函数创建,使用semctl()函数控制,使用semop()函数进行操作。
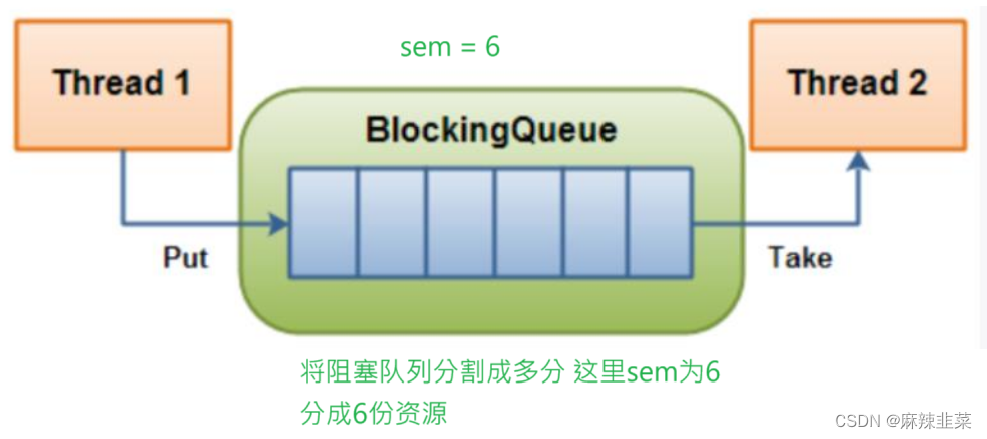
文档的话太抽象了,下面我用大白话来解释信号量
我们将阻塞队列比喻成电影院,而信号量就如同电影票,电影院是一个整体的公共资源,那么电影院的座位就把电影院这个整体划分为无数份的资源。而信号量就是预定座位资源。
那么当我们购买电影票成功或不成功,对应编程来说,其实就是在访问临界资源的同时进行了临界资源就绪或者不就绪判断。
就绪意味者线程可以访问
不就绪意味着线程不可访问
POSIX 信号量的基本操作:
初始化:使用 sem_init() 初始化一个无名信号量
int sem_init(sem_t *sem, int pshared, unsigned int value);sem:指向信号量变量的指针。pshared:非零表示信号量可以被其他进程访问,零表示只能在当前进程内访问。value:信号量的初始值。
等待(减):使用 sem_wait() 或 sem_trywait() 减少信号量,如果信号量的值大于零,则减少其值,否则进程将等待。
int sem_wait(sem_t *sem);
int sem_trywait(sem_t *sem);信号量值增加(信号):使用 sem_post() 增加信号量的值,如果其他进程因为信号量的值小于或等于零而等待,则其中一个进程将被唤醒。
int sem_post(sem_t *sem);获取信号量值:使用 sem_getvalue() 获取信号量的当前值。
int sem_getvalue(sem_t *sem, int *sval);销毁信号量:使用 sem_destroy() 销毁一个无名信号量。
int sem_destroy(sem_t *sem);这些接口使用起来还是比较简单,下面我们用信号量来实现生产消费者模型。前面用的是阻塞队列,我们用信号量实现基于循环队列版本。
4. 基于循环队列实现生产消费者模型
在实现之前我们先了解循环队列这种数据结构。我们利用数组这种数据结构,然后对下标进行取模可以让数组变成循环的结构

一张动图搞定循环队列这种数据结构
这里有几个关键问题:
问题1:生产者关注什么资源?消费者关注什么资源?
生产者关注的是数组还有多少空间、消费者关注的是数组还有多少数据。
问题2:生产者和消费者什么时候才会指向同一个位置?
要么数组为空、要么数组为满。(这两种状态只能是生产和消费其中一个进行访问,空生产者访问、满消费者访问。)
反之一定是指向不同的位置 (这句话非常重要,意味着生产和消费可以同时访问)
那么循环队列要正常运行必须满足3个条件
1. 空或者满只能有一个人访问
2. 消费者一定不能超过生产者
3. 生产者一定不能套圈消费者
如果消费者超过生产者,前面都没有数据,访问什么?
为什么这么说?因为最开始一定为空。那么一定是生产者先走!毫无疑问
如果生产者套圈消费者意味着生产速度大于消费速度之前没有消费的数据要被覆盖。数据出现覆盖,严重错误。
理解了这些问题我们直接多生产多消费来实现
4.1 多生产多消费
老规矩先创建RingQueue.hpp头文件
#include <iostream>
#include <vector>
#include <pthread.h>
#include <semaphore.h>
const static int defaultcap = 5;
template <class T>
class RingQueue
{
public:
RingQueue(int cap = defaultcap)
: _ringqueue(cap), _cap(cap), _c_step(0), _p_step(0)
sem_init(&_cdata_sem, 0, 0);
sem_init(&_pspace_sem, 0, cap);
pthread_mutex_init(&_c_mutex, nullptr);
pthread_mutex_init(&_p_mutex, nullptr);
}
void push(const T& data)
{
}
T pop(T* out)
{
}
~RingQueue()
{
sem_destroy(&_cdata_sem);
sem_destroy(&_pspace_sem);
pthread_mutex_destroy(&_c_mutex);
pthread_mutex_destroy(&_p_mutex);
}
private:
std::vector<T> _ringqueue; // 循环队列
int _cap; // 循环队列容量
int _c_step; // 消费者下标
int _p_step; // 生产者下标
sem_t _cdata_sem; // 消费者关注的数据资源
sem_t _pspace_sem; // 生产者关注的空间资源
pthread_mutex_t _c_mutex; // 消费者锁
pthread_mutex_t _p_mutex; // 生产者锁
};框架大致构建出来,为了方便生产消费的互斥与同步。我们接下来对生产和消费线程互斥与同步的函数进行封装
void Lock(pthread_mutex_t &mutex)
{
pthread_mutex_lock(&mutex);
}
void UnLock(pthread_mutex_t &mutex)
{
pthread_mutex_unlock(&mutex);
}
void P(sem_t &sem) //减少
{
sem_wait(&sem);
}
void v(sem_t &sem) //增加
{
sem_post(&sem);
}
实现push 和 pop函数
void Push(const T &data)
{
P(_pspace_sem);
Lock(_p_mutex);
_ringqueue[_p_step++] = data;
_p_step %= _cap;
UnLock(_p_mutex);
V(_cdata_sem);
}
T Pop(T *out)
{
P(_cdata_sem);
Lock(_c_mutex);
*out = _ringqueue[_c_step++];
_c_step %= _cap;
Unlock(_c_mutex);
V(_pspace_sem);
return out;
}这里解释push函数P操作为什么传入的是空间信号量,很简单生产者关注的是空间资源,所以这里P判断空间资源就不就绪,V为什么传入的是数据信号量?当P申请成功意味着可以生产,那么对应空间资源减少,数据资源增加。
同理pop也是一样。
我们mian.cc创建线程 和回调函数
#include <unistd.h>
#include <mutex>
#include <ctime>
#include "RingQueue.hpp"
#include "Task.hpp"
std::mutex _mutex;
void *consumer(void *args)
{
RingQueue<Task> *rq = static_cast<RingQueue<Task> *>(args);
while (true)
{
Task t;
rq->Pop(&t);
t();
std::lock_guard<std::mutex> guard(_mutex);
std::cout << "处理任务: " << t.GetTask() << " 运算结果是: "
<< t.GetResult() << " thread id: "<< std::hex << pthread_self() << std::endl;
}
}
void *productor(void *args)
{
RingQueue<Task> *rq = static_cast<RingQueue<Task> *>(args);
int len = opers.size();
while (true)
{
sleep(1);
int data1 = rand() % 10 + 1;
int data2 = rand() % 10;
char oper = opers[rand() % len];
Task t(data1, data2, oper);
rq->Push(t);
std::lock_guard<std::mutex> guard(_mutex);
std::cout << "生产了一个任务: " << t.GetTask() << " thread id: " << std::hex << pthread_self() << std::endl;
}
}
int main()
{
srand(time(nullptr) ^ getpid()); // 随机数种子
RingQueue<Task> *rq = new RingQueue<Task>(40);
pthread_t c[3], p[3];
for (int i = 0; i < 3; i++)
{
pthread_create(c + i, nullptr, consumer, rq);
}
for (int i = 0; i < 3; i++)
{
pthread_create(p + i, nullptr, productor, rq);
}
for (int i = 0; i < 3; i++)
{
pthread_join(c[i], nullptr);
}
for (int i = 0; i < 3; i++)
{
pthread_join(p[i], nullptr);
}
delete rq;
return 0;
}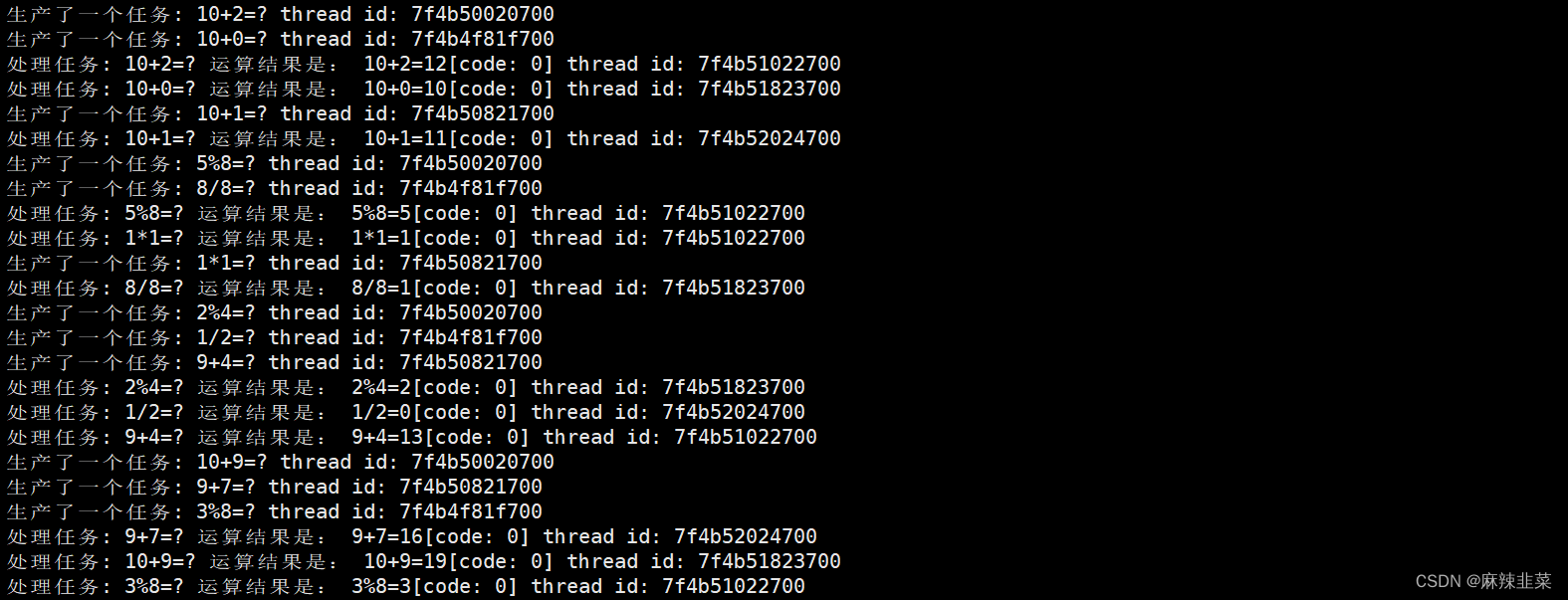
这里打印只打印了线程ID,我们可以重新创建一个线程名字的类。把线程名字加入进去
struct ThreadData
{
RingQueue<Task> *rq;
std::string threadname;
};
细节: 加锁行为放在信号量申请成功之后,可以提高并发度


为什么这么说,信号量在加锁之前就好比,没进电影院之前就已经选好了座位,如果在加锁之后,那就如同进到电影院之后在选座位,而再选座位就又得排队买票。而且信号量本身就是原子操作。
那既然阻塞队列也能实现生产消费者模型,那搞出来个循坏队列又有什么用?
环形队列的优缺点:
优点:
- 空间利用率高:由于是环形结构,已使用的空间可以重复利用,不会像普通队列一样造成空间的浪费。
- 插入和删除速度快:由于是线性结构,环形队列的插入和删除操作通常很快,因为它们只涉及到头尾指针的移动。
- 固定大小的存储空间:可以避免内存泄漏等问题,因为不会动态地分配和回收内存。
缺点:
- 需要额外的指针维护状态:增加了复杂度,需要维护队列头和队尾的指针。
- 存储空间可能未被充分利用:一旦队列满了,就需要覆盖队列头的元素,这可能导致存储空间没有被完全利用。
- 队列大小必须预先定义:难以动态调整大小,这在某些需要灵活内存使用的场景下可能是一个限制。
阻塞队列的优缺点:
优点:
- 线程同步:阻塞队列可以很好地实现线程之间的同步,简化了生产者和消费者之间的数据传递和通信。
- 解耦合:作为生产者消费者模式的缓冲空间,阻塞队列降低了生产者和消费者之间的耦合性。
- 削峰填谷:由于阻塞队列的大小是有限的,它可以起到限制作用,平衡突发的流量高峰。
缺点:
- 可能引发死锁:如果使用不当,比如生产者和消费者互相等待对方释放资源时,可能会发生死锁。
- 对性能的影响:线程的挂起和唤醒操作可能会对系统性能产生影响,尤其是在高并发场景下。
- 处理超时操作较复杂:在设置了超时时间的情况下,需要处理超时异常并进行相应的补偿或回滚操作,增加了编程复杂性。
每种数据结构都有其特定的使用场景和限制,开发者在选择时应根据具体需求和上下文来决定使用哪一种。
本篇我们学习了什么是生产消费者模型,基于两种数据结构,分别实现了生产消费者模型,
还掌握了一个线程同步神奇——信号量。这对于提高线程之间的并发度非常有用。再次理解了生产消费者模型为什么高效?总之生产消费者模型非常值得我们学习。